1. 引言
水是一种巨大的自然资源,水资源在饮用水、农业、娱乐和工业用水等各种方面都至关重要,但这些水资源很大程度上会受到工业、人类行为或其他自然过程的污染,对环境和人类健康都产生了直接影响,导致疾病和死亡率持续增加,准确、灵敏的水质预测模型,能够有效的服务于水污染的治理和水资源的利用,因此对水质进行预测是非常必要的一项研究。
水质预测研究主要集中在机器学习模型研究方面,由于机器学习模型在处理非线性等复杂数据时具有更高精度、鲁棒性、有效性以及可靠性,因此在处理水质相关数据方面有显著的优势。heddam等人 [1] 使用了具有乙状激活功能、放射状、在线顺序和最佳修剪特性的elm神经网络模型,并与mlp和mlr进行了比较,对溶解氧指标进行预测,实验证明此elm神经网络模型预测溶解氧的准确性更高。mitrović 等人 [2] 采用了18个水质特征指标作为蒙特卡洛模拟的ann模型的输入量,采用wq单变量输出的方式,对水质进行预测,模型预测效果优秀,适用于多目标场景,具有高精度、效率高等特点。tiwari等人 [3] 采用多输入变量对水质指数(wqi)进行预测,此研究采用了两种聚类技术,即模糊c-均值(fcm)和基于anfis的减法聚类(sc1-anfis),通过实验证明,sc1-anfis对wqi的预测性优于fcm。rankinen 等人 [4] 提出了可管理非正态误差分布的广义线性模型(glm)和可处理非线性和缺失数据的增强回归树(brt)模型,考虑到气候变化、农业措施和环境政策等间接因素,对未来各种情景下的水质情况进行预测。ahmed [5] 等使用两个ann模型(即ffnn和rbfnn)预测surma河的溶解氧(do),实验发现两个ann模型都具有较好的预测能力,相对而言ffnn比rbfnn预测精度更高一些,此水质预测模型可以应用于水管理和处理系统。查文舒等 [6] 通过全连接神经网络、卷积神经网络、循环神经网络等多种网络结构进行微分方程的求解,大幅提高泛化能力与应用价值。张皓等 [7] 提出一种多重t-s型模糊神经网络pid温度控制算法,利用t-s型模糊神经网络的单输出特性,建立能分别输出pid3个参数的3重网络模型,模型稳定性高,抗干扰能力强。李晶晶等 [8] 以长短期记忆(lstm)网络为基础提出了一种新的数据驱动空间负荷预测方法,分析神经网络内部的时序,避免数据消沉现象,确定训练数据空间的相关性,提高了预测速度。陆继翔等 [9] 提出了一种基于卷积神经网络(cnn)和lstm网络的混合模型短期负荷预测方法,将海量的历史负荷数据、气象数据、日期信息以及峰谷电价数据按时间滑动窗口构造连续特征图作为输入,先采用cnn提取特征向量,将特征向量以时序序列方式构造并作为lstm网络输入数据,再采用lstm网络进行短期负荷预测,预测精度得到明显提升。
在水质预测的相关研究中,存在着影响因子众多、数据指标复杂以及单一模型预测精度低等问题,因此本文采用主成分分析方法(pca)作为特征选择的方法,采用xgboost作为预测模型,并利用麻雀搜索算法(ssa)对xgboost模型的参数进行优化。
2. 关键技术
2.1. pca主成分分析
主成分分析法作为多元统计中的重要部分,是一种较为常见的无监督的数据降维方法,通过某种线性投影,将高维的数据映射到低维的空间中,并使得投影中维度上的数据方差最大。
假设有n个样本,且每个样本有p个变量,则可以构成一个n × p的原始数据矩阵,将原始数据进行标准化处理,计算方法如(1)所示:
(1)
式中,
为标准化后的数据,
为原始数据,
是第i个指标的样本均值;
为第i个指标的标准差。
基于标准化的矩阵,计算相关系数r。根据相关系数矩阵r的特征方程,求解r的特征值和特征向量,r的特征值为
且
,
是主成分特征向量所对应的特征值,即各主成分的方差值,其大小代表了原始样本在主成分中所占的比重,每个特征值对应的特征向量为
,通过这些特征向量把标准化的指标转化为主成分 [10] ,计算方法如(2)所示:
(2)
计算贡献率
和累计贡献率
,计算方法如(3) (4)所示:
(3)
(4)
确定主成分并计算各主成分综合得分:首先要确定主成分的个数,主要方法有两种 [11] [12] ,一是主成分方差累计贡献率大于80%、二是各主成分特征值大于1.0,然后由主成分的方差贡献率通过加权求和法得出主成分的综合得分。
2.2. xgboost算法
xgboost是基于cart树的一种boosting算法,它是通过多个学习器的学习,来不断降低模型值和实际值的差。其基本思想是不断生成新的树,每棵树都是基于上一颗树和目标值的差值来进行学习。模型输出表达式为
,其中:k为树的总个数,
表示第k颗树,
表示样本
的预测结果。
模型的目标函数由两部分组成,一是模型误差,即样本真实值和预测值之间的差值,二是模型的结构误差,即正则项,用于限制模型的复杂度。目标函数的计算方法如(5)所示
(5)
其中:
为样本
的损失函数,
表示第k颗树的正则项。
xgboost通过不断地分裂添加树,每次添加树的过程即为学习一个新函数
,去拟合前一次预测的残差。当训练完成得到k棵树,对样本的分数进行预测,每个叶子节点对应一个分数,将每颗树的分数相加即可得到该样本的预测值。计算方法如(6)所示:
(6)
其中:
表示第k棵树,
表示组合t棵树模型对样本
的预测结果。
优化目标函数。损失函数采用均方误差,目标函数为:
(7)
对于目标函数中的正则项,从每一棵回归树考虑,其模型可表示为:
(8)
其中:
为叶子节点q的分数,
表示样本x对应的叶子节点,t为该树的叶子节点个数。
为其中一棵回归树。
为了避免过拟合,对树上叶子节点的分数
进行正则化,xgboost的目标函数可写为:
(9)
其中:
为叶子个数,
表示
的l2模平方。
利用泰勒展开式去将目标函数进行进一步的变形,且令
,
,由于在第t棵树,
是真实值,即已知,第t颗回归树是根据前面的t − 1颗回归树的残差得来的,相当于
t − 1颗树的值
是已知的,因此
是常数。去除所有常数项,并将
看
作是每个样本在第t棵树的叶子节点的分数相关函数的结果之和,则目标函数可表示为:
(10)
式中:t为第t棵树中总叶子节点的个数;
表示在第j个叶子节点上的样本;
为第j
个叶子节点的分数值。定义
,
,通过对
求导等于0,可以得到
,则
目标函数表示为:
(11)
2.3. 麻雀搜索算法
麻雀作为一种群居类动物,种类繁多,对环境的适应性较强,有较高的灵敏度,飞行能力强。在麻雀觅食过程中,具有不同的分工,具体可以分为发现者和加入者。发现者和加入者的身份是动态切换的,只要能够寻找到更丰富的食物来源,每只麻雀都可以成为发现者,但发现者和加入者所占整个种群数量的比重是不变的。
假设麻雀种群的初始规模数是n,用
表示。d表示麻雀个体所附带的维度。算法中,发现者有较强搜索能力即具备较好适应度值,因此更容易搜寻到食物。在整个空间中,其位置更接近最优解的位置。在每轮迭代搜索的过程中,发现者会进行位置更新,计算方式为:
(12)
其中,
表示种群中第i只麻雀在第j维的位置;t是算法当前的迭代次数,
是最大迭代次数;
是(0, 1]之间的随机值;r的取值范围是[0, 1],表示算法中麻雀个体遇到危险时的预警值;st的取值范围是[0.5, 1],表示安全值;q是服从正态分布的随机数;l表示大下为
,元素都是1的矩阵。
当
时,表示部分麻雀已发现危险,发现者按正态分布随机移动到当前位置附近。当
时,表示此时麻雀群体搜索的环境周围不存在危险,发现者可以进行大范围的搜索操作,往外搜索食物。随
着种群迭代次数的增加,
项的取值范围将随之减少,即对应到麻雀个体的每一维上的值都
将减少。
当一些加入者找不到食物补充能量时,会监控发现者在捕食过程中的行为。当发现者搜索到丰富的食物后,加入者会离开自己所在的位置去抢夺发现者的食物,如果能够抢到食物就会进行补充能量,否则会被迫去其他区域觅食。加入者的位置更新描述如下:
(13)
其中,
表示发现者适应度值最优的位置;
表示当前空间中适应度值最差的位置;a是维度
,
元素都是1或者−1的矩阵;
满足关系式
。当
时,表明该加入者处于十分饥饿的状态,利用一个标准正态分布随机数与以自然对数为底指数函数的积,控制其取值符合正态分布,即获取更多的能量。当
时,其过程可解释为在当前最优位置附近随机找到一处位置,且每一维据最优位
置方差较小,值较为稳定。
觅食过程中麻雀个体遇到危险时,会往内部或者其他同伴靠拢。该过程的麻雀个体更新位置的方法如下:
(14)
其中,
是当前的全局最优位置;
表示步长控制参数,满足均值为0,方差为1的正态分布的随机值;k是[−1, 1]之间的随机值,表示麻雀的移动方向;
是接近零的常数,防止分母为0的情况出现;
表示第i只麻雀的适应度值;
和
表示当前麻雀种群的最优和最差适应度值。当
时,表示第i只麻雀的在觅食圈的外围,较容易受到外来者的攻击;当
时,表示一些麻雀意识到了危险,需要向周围的同伴靠拢来保障自己的安全 [13] 。
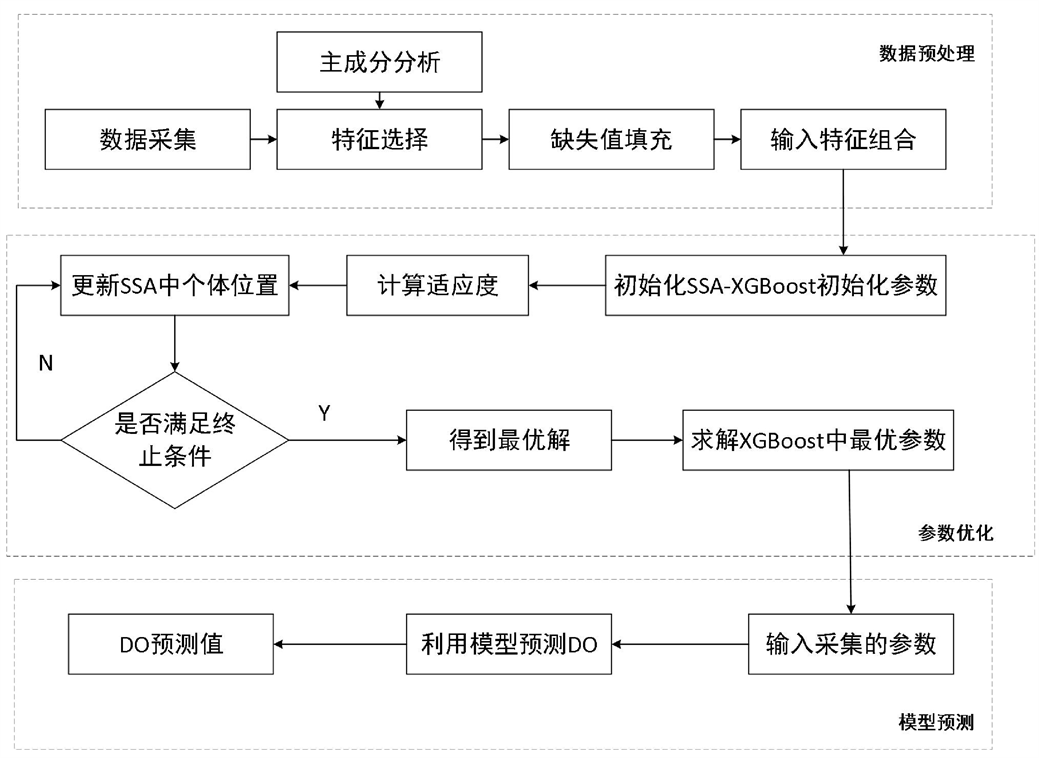
3. ssa-xgboost模型预测模型建立
准确、灵敏的水质预测模型对水资源的有效利用和管控具有重要意义,由于溶解氧与水质指标参数具有复杂的非线性关系,且单一模型对水质预测精度欠佳,因此本文提出了基于xgboost的水质预测模型,通过麻雀算法中个体位置的更新,实现对xgboost中参数的优化。本文选取溶解氧作为模型输出,以此来准确高效的判断水质情况。溶解氧是指溶到水体中的分子氧,其来源主要包括水体和大气平衡状态下溶解到水体中的氧以及水体中进行化学、生物反应形成的氧。水中的溶解氧含量如果较高将会有利于水中污染物的降解,可以加快水的净化速度,如果溶解氧的含量较低则水中污染物降解的速度较慢。溶解氧不仅是衡量水质的重要指标,也是水体净化的重要因素。因此采用溶解氧作为衡量水质的标准,通过预测溶解氧实现对水质的预测。
通过缺失值填充、特征选择和参数优化三个方面结合,提出水质预测模型ssa-xgboost。溶解氧的影响因素包括ph、电导率、浊度、高锰酸钾指数、氨氮、总磷、总氮。针对溶解氧影响因素众多且关系复杂的问题,本文通过pca方法对水质参数进行相关性分析以选择模型的输入特征,减少冗余信息导致的误差,降低问题复杂度。而针对采集数据中存在缺失值的问题,通过皮尔逊系数对不同缺失值填充方法进行分析比较,以此寻找最优的缺失值填充方法。
其具体实现步骤如下:
步骤1. 对水质相关数据进行采集。
步骤2. 根据主成分分析从候选参数中选择输入特征,降低问题复杂度。
步骤3. 通过皮尔逊系数对不同缺失值填充方法进行分析,选择最优的缺失值填充方法。
步骤4. 初始化设置水质预测模型的种群数量pop为30,对个体的位置、种群边界和最大迭代次数进行初始化,计算适应度值。
步骤5. 根据适应度函数更新个体的位置。
步骤6. 判断是否满足终止条件,终止条件即达到最大迭代次数或适应度值达到设定阈值,满足终止条件则输出xgboost最优参数,否则返回步骤4。
步骤7. 以获取到的最优参数代入到xgboost中,得到水质预测模型。
步骤8. 在线运行阶段,根据采集的参数计算输入特征,并利用xgboost模型进行水质预测。
模型的处理流程如图1所示。
4. 实验分析
4.1. 特征选择与数据预处理
本文使用的数据取自2023年2月1日至5日的上海市太湖流域以及长江流域的明星路桥、临江、吴淞口、前卫村桥、七效港西桥等19个断面的551个水质样本数据,监测站点每4小时发布一次实时数据。在模型建立前要对数据进行降维处理,确定影响水质溶解氧的变量数目,使得样本数据更为直观方便。首先利用主成分分析方法计算出水质指标的累计方差贡献率,将方差贡献率累加大于80%的指标作为选取的特征变量,各特征的方差贡献率如图2所示,其中电导率、浊度、高锰酸盐指数和总磷四个参数的方差贡献率累加超过80%,因此选用电导率、浊度、高锰酸盐指数和总磷作为水质预测模型的输入变量。
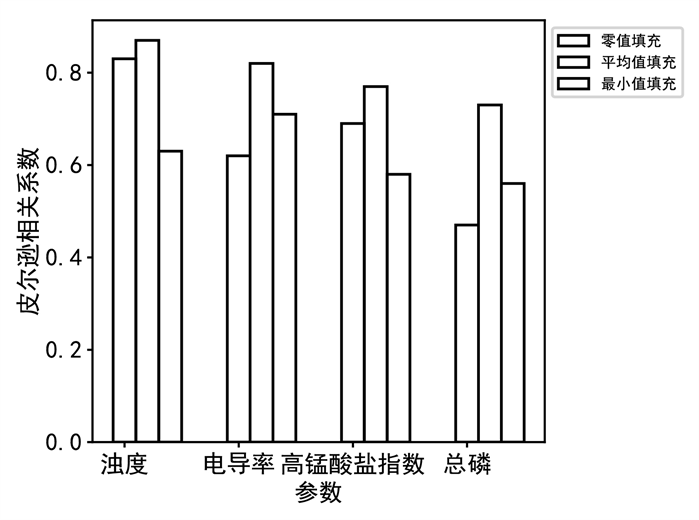
对于样本数据由于温度、传感器故障、检验操作步骤等情况存在数据缺失的问题,为了提高预测准确度,需要对数据进行预处理。根据本文数据特点采用零值填充、平均值填充、最小值填充三种缺失值填充方法对样本数据进行填充,并通过皮尔逊相关系数(pearson correlation coefficient)对不同缺失值填充方法效果进行评估,其中皮尔逊相关系数计算公式如式(15)所示:
. model flowchart
图1. 模型流程图

. variance contribution rate of each feature
图2. 各特征方差贡献率
(15)
其中,para为水质指标,cov(para, do)为水质指标和溶解氧(do)之间的协方差,
和
为水质指标和溶解氧的标准差。
取值范围为[−1, 1],其中皮尔逊系数越接近1,代表水质指标与do的相关性越高。
不同缺失值填充方法的皮尔逊系数对比图如图3所示。为节约计算成本,采用不同的缺失值填充方法,选取对do影响程度最大的4个参数进行相关性分析,其中图2为参数与do的皮尔逊相关系数对比情况,采用平均值填充方法使参数与do的相关性有显著提升。
. pearson coefficient analysis of different missing value filling methods
图3. 不同缺失值填充方法皮尔逊系数分析
4.2. 仿真环境与评价指标
基于ssa-xgboost的溶解氧预测模型是在intel(r) core(tm) i7-10510u (8核),内存16 gb,win10 64 位操作系统,编程语言为python的开发环境中进行仿真实验。采用ssa对学习目标参数进行优化。n_estimator为学习器的数量,learning_rate为学习率,max_depth = 365为叶最大深度,gamma为损失减小阈值。优化后的xgboost在训练过程中的参数取值为n_estimator = 417,learning_rate = 0.51,max_depth = 365,gamma = 0.83。
为了更准确的验证模型的预测效果,本文采用均方根误差(rmse)、平均绝对误差(mae)、决定系数(r2)的两个评价指。如式:
均方根误差(rmse):
(16)
平均绝对误差(mae):
(17)
决定系数(r2):
(18)
式中,
为第t天的溶解氧含量;
为第t天的溶解氧含量的预测值;n为预测样本数。均方根误差是来衡量观测值同真值之间的偏差,rmse指标越小,说明模型的预测精度越高;决定系数是用来评价模型系数拟合优度,r2越大越好。当预测值与真实值完全一致时,r2达到最大值1。
4.3. 不同数据量的模型性能评价
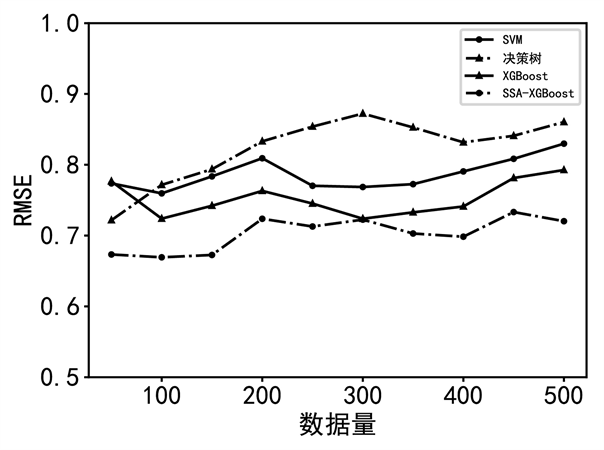
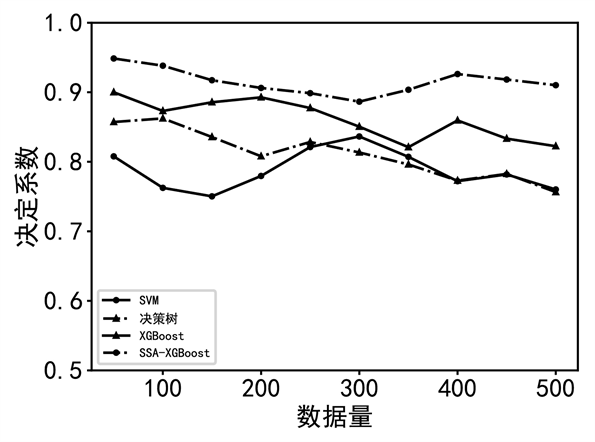
为测试模型在不同规模数据集中的性能,本文取500条样本数据分为10组,每组五十条,在不同数据量下进行实验,以证明模型在不同数据量下的鲁棒性,采用ssa-xgboost模型进行仿真实验并对预测结果进行了统计分析,如图4~图6所示。
. rmse under different data volumes
图4. 不同数据量下的rmse

. mae under different data volumes
图5. 不同数据量下的mae
. coefficient of determination under different data volumes
图6. 不同数据量下的决定系数
由图可知,随着训练数据集中样本数量从100~500变化,ssa-xgboost的rmse和决定系数虽有波动,但总体保持平稳,在不同数据量情况下,ssa-xgboost都具有最小的rmse、mae和最大的决定系数,而其他模型的性能则随数据量增加出现明显的下降。
4.4. 与现有方法性能的比较
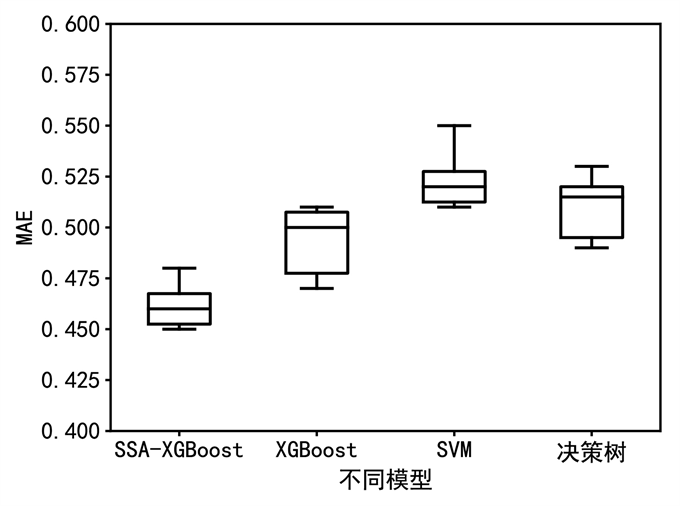
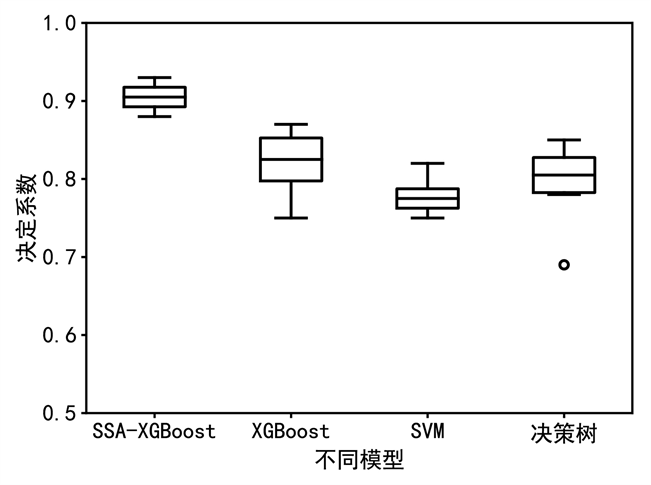
在进行水质指标溶解氧的预测问题时,将经过主成分分析特征选择的溶解氧数据作为ssa-xgboost预测模型的输入,取80%的数据为训练集,20%数据为测试集,并与支持向量机(svm)、xgboost、决策树、ssa-xgboost预测模型进行对比分析,由图7~图9可知,ssa-xgboost的均方根误差和决定系数都具有最好的性能且波动较小。
4.5. 预测结果
采用ssa-xgboost模型对溶解氧进行预测,取数据集中的70%作为模型的训练集,取数据集中的30%作为模型的测试集,在不同实验条件下,ssa-xgboost模型都具有最好的预测性能,在测试集中对溶解氧真实值和ssa-xgboost预测值进行对比,如图10所示。由图可知,采用ssa-xgboost模型的预测值和真实值拟合程度较高,具有良好的预测能力。

. rmse under different models
图7. 不同模型下的rmse
. mae under different models
图8. 不同模型下的mae
. coefficient of determination under different models
图9. 不同模型下的决定系数

. prediction results
图10. 预测结果图
5. 结论与展望
本文采用主成分分析(pca)进行特征选择,结合麻雀搜索算法和xgboost算法,提出了ssa-xgboost预测模型,以最优超参数实现水质预测。研究采用pca分析水质指标与溶解氧之间的相关性,确定了预测模型的输入特征,降低了变量之间的耦合性,消除了信息冗余对预测精度的影响,通过皮尔逊系数分析方法确定了最优缺失值填充方法为平均值填充。实验通过ssa-xgboost、svm、xgboost、决策树四种算法对上海市的水质指标溶解氧进行预测,测试结果表明,本文提出的ssa-xgboost方法预测误差更小,且该方法预测结果的rmse、r2波动均优于其他现有模型。表明ssa-xgboost模型可以更好地预测上海地区未来的水质变化。
notes
*通讯作者。