1. 引言
智能交通系统作为当前智能交通的核心技术体系,将先进的信息技术运用于整个交通运输系统,通过对交通进行合理的引导和控制来提高交通运输效率,提高路网通行能力 [1] 。智能交通系统已经在缓解交通问题方面发挥了重要作用,通过合理的车辆疏导和管理,能够缓解路段交通压力、避免交通拥堵,提高城市交通系统的性能 [2] [3] 。智能交通系统可以利用历史交通流数据进行数据分析,进而对未来交通流做出合理预测,提供数据支持以支持交通控制、交通网络规划和缓解交通压力等工作 [4] 。所以准确可靠的交通流量预测是当下的研究热点。
在过去的几十年里,国内外针对短期交通流预测已经做出了大量研究。连续采集同一地点的交通流,使得交通流预测成为一个典型的时间序列预测问题,利用时间相关性,考虑交通数据过去状态与未来状态的变化特性进行预测,提出了许多线性模型。传统的线性模型主要包括自回归模型(autoregressive model, ar) [5] 、滑动平均模型(moving average model, ma) [6] 、历史平均模(historical average model, ha) [7] 等,这些模型采用最小二乘法估计参数,对平稳序列的研究有一定效果;为适应时间序列的非平稳变化,在此基础上提出了自回归滑动平均模型(auto regression integrated moving average, arima) [8] [9] [10] ,其通过对非平稳的交通流数据差分处理,使其平滑化后进行研究;由于arima模型的预测效果显著,在此后学者提出了arima的变形,如季节arima [11] 、karima [12] 、arimax [13] 模型等。虽然上述模型具有一定的预测能力,但是由于交通流不确定性的特点,不能充分反映交通流的非线性变化。为了适应交通流的非线性变化,非参数模型被提出并成功应用到交通流预测领域 [14] [15] [16] 。接着,更先进的算法被提出来提高预测的精度,如k近邻(k-nearest neighbor, knn) [17] [18] [19] 、支持向量回归(support vector-regression, svr) [20] [21] [22] 、非参数回归 [23] 以及这些模型的组合。这类模型较为简单,但是对于复杂数据的处理能力不足,模型的预测精度较低。
交通流量预测是一个紧密联系着城市化、交通拥堵、交通智能化和交通规划等多个方面的研究领域,受到了广泛关注和研究。交通流量预测通过对未来交通流量进行估计,可以在交通管理和规划中发挥重要作用。通过预测交通流量情况,可以确定哪些路段拥堵严重,从而提出相应的路网优化方案。在特定时间和地点,如果预计出现拥堵,可以通过改变信号灯时长、引导车辆绕行等措施进行交通疏导。预测未来交通流量可以为公共交通规划提供有力的支持,如优化公交线路、增加车辆班次等。在交通事故等情况下,通过预测结果可以帮助交通部门快速做出反应,如调度交通警力、安排交通管制等。因此,交通流量预测对于交通管理和规划具有重要作用,能够提高交通系统效率、减少拥堵和事故,从而提升城市居民的生活质量。
2. 张量原理及短时交通流量预测
2.1. 张量原理
张量(tensor)是一个多维的数据存储形式,数据的维度被称为张量的阶,是向量和矩阵在多维空间中的推广。一般一维数组,称之为向量(vector);二维数组,称之为矩阵(matrix);三维数组以及多位数组,称之为张量(tensor)。高阶张量即为利用多个变量反应数据的变化规律,即向量和矩阵在多维方向上的拓展。建立四维张量结构,可同时对时间、空间、天和周四个维度进行建模,在不破坏原始数据高维结构之间的约束关系的前提下,能对四个维度进行分析处理,从而挖掘数据中更深层的信息,达到更准确的预测效果。张量理论包括张量分解理论和张量填充理论,前者通过部分数据估算缺失数据,后者利用已知数据和未知数据的内在关联来预测未来数据。这一原理与短时交通流预测理论相符,研究表明交通流数据具有多模式相关性和低秩性,适用于张量填充理论。
2.2. 张量填补研究
2.2.1. 张量cp分解
hitchcock于1927年提出一种张量的分解方法,他假设如果一个张量的秩为r,那么可以该张量表示成有限个秩一张量之和的形式,简称为cp分解。定义三阶张量为
。
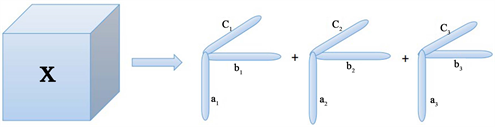
. cp decomposition diagram of the tensor
图1. 张量的cp分解示意图
图1的公式可以表示为
其中
是由kolda提出的关于cp分解模型的缩写表示,a,b,c表示因子矩阵,它们的大小分别为
,
,
,表示张量在三个维度上的主成分,r为该张量的秩,λ为系数组成的长度为r的向量。在公式中,张量x和因子矩阵之间的对应关系也可以如下式表示:
的维度分别
,
,
。于是,如何用cp分解模型填补原始张量的问题就转变成以下公式的误差最小化问题:
即找到合适的参数λ,a,b,c和r,根据cp分解模型公式求得填补张量
和原始张量x之间误差的范数最小化,问题将转变成典型的数值优化问题。通过cp分解模型公式,找到合适的参数,λ,a、b、c和r,然后根据公式计算填补张量和原始张量x之间的误差范数最小值。基于cp分解张量补全算法见表1。
. tensor completion algorithm based on cp decomposition
表1. 基于cp分解的张量补全算法
2.2.2. 张量的tucker分解
tucker分解模型是tucker等人于20世纪60年提出的一种关于张量因子分解的理论方法,又称为高阶奇异值分解。它是在矩阵svd分解的基础上推广到高维多线性问题的一种方法。tucker分解可以看作是一种将高阶张量分解为一个核张量和若干个因子矩阵的乘积形式,从而可以对张量的多维结构进行更好的描述和分析。
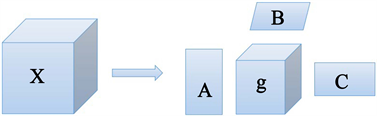
. tucker decomposition diagram of the tensor
图2. 张量的tucker分解示意图
图2 tucker分解可以表示为:
其中
表示张量的tucker分解中对应的核心张量,它表示张量的不同维度之间的关联程度。矩阵
,
,
均表示因子矩阵,通常为正交矩阵,其中p,q,r为分别因子矩阵a,b,c列向量的数量。
为tucker分解模型的缩写形式。张量x的元素值与核心张量及因子矩阵的元素值之间的对应关系如下式表示:
对于tucker分解算法,其核心思想与cp分解算法类似,同样将问题转换成求填补张量和原始张量之间的误差范数最小化的优化问题,不同的是tucker算法中,涉及到新的变量即核心张量g,而核心张量g在结构上可以认为是原始张量的压缩形式,kolda和bader曾在他们的研究中提出tucker分解模型由于其所占的存储空间要比原始张量小很多的优势,可以用于进行数据压缩。基于tucker分解张量补全算法见表2。
. tensor completion algorithm based on tucker decomposition
表2. 基于tucker分解的张量补全算法
3. 基于张量的短期交通流量预测算法
3.1. 交通流数据的周期性和多模态性
交通流数据的周期性特点与人们的生活节奏和出行方式密切相关,因为人们的有规律的出行导致交通流数据呈现出以天、周为周期的规律。具体如下图所示。

. schematic diagram with a period of days
图3. 以天为周期示意图
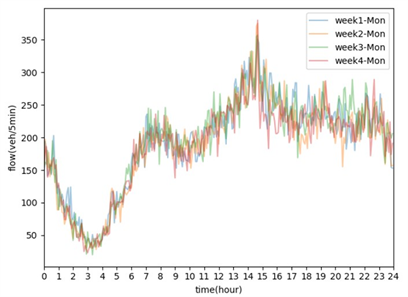
. schematic diagram with week as period
图4. 以周为周期示意图
在图3和图4中可以看出,由于人们出行工作或者上学等周期性行为,使得一周当中周一到周五的交通流量数据呈现出明显的周期性现象。同样,在以每周作为周期性单位时,也呈现出强烈的周期性现象。

. correlation between adjacent lows
图5. 相邻低点之间的相关性
从图3、图4和图5中可以看出,现实生活中真实的交通流量数据的特性不仅体现在未来数据和历史数据的时间维度相关性,还体现在交通流量数据按照以天和周为单位的周期性,以及空间维度的相关性,因此,在本文的研究中,提取出交通流量数据的四个模式即时间,空间,天和周上的特征进行建模,将其构建成形式为time × day × week × location的四维张量结构。
3.2. 基于张量结构的交通流量数据模型分析
通过上述的分析可以得出,预测短期交通流量数据可以从时间(time),空间(location),天(day)和周(week)这四个模式进行分析,将以这四个模式构建基于交通流量数据的四维张量,形式为:
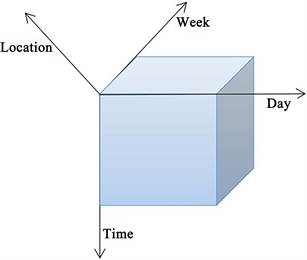
. four-dimensional traffic tensor structure based on traffic flow data
图6. 基于交通流量数据的四维交通张量结构
图6为张量模型,张量中的元素表示对应坐标下的交通流量值,引入张量分解模型则得到对应的交通张量分解模型公式如下:
在该交通张量分解模型中,交通张量
,以每五分钟为单个时间片,则每天将会产生288个时间片,一周选取7天,连续选择8周的相邻24个地点的历史数据。
4. 短期交通流预测实验分析
4.1. 交通流量数据介绍
美国高速公路数据来源于美国加利福尼亚州高速公路系统pems中开源的交通流量数据库,本文数据收集于第七区,时间从2014年5月1日到2014年6月26日,共计56天的历史数据。交通流量数据格式为每五分钟采集一次。全天共计288个时间点,来自于24个检测点。该数据的优势在于pems系统中,每个检测点每隔五分钟会采集当前经过的车流量,并将采集到的数据上传到数据库,除此之外,该系统中自带缺失值填补算法,能够将因传感器故障而导致的缺失数据自动进行填补,因此采集到的数据不再需要过多的预处理过程,但其同样存在缺点,因为只能获取到车流量信息,而无法得到当时的交通状况信息,因此对于异常的交通流量值,无法得知其是因为真实的交通情况异常导致还是数据收集时的误差导致。图7是位于检测点1的56天的交通流量数据,图8是位于检测点3的56天的交通流量数据。
4.2. 短期交通流量预测
在本小节中,将基于预处理之后完整的交通流量数据集,对文中提出的预测算法和传统的预测算法进行实验对比,算法主要有tucker-als和对比算法:cp-als、非负矩阵分解(nnmf)、arima算法。作为预测算法准确度的评价指标,本文采用mae (平均绝对误差)、mape (平均绝对百分比误差)、rmse (均方根误差)其中,评价公式为:
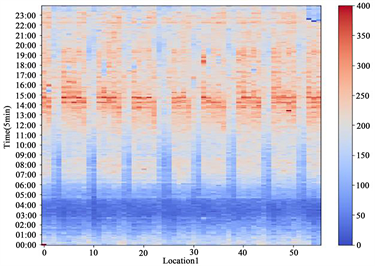
. traffic flow data for 56 days at monitoring point 1
图7. 位于监测点1的56天的交通流量数据
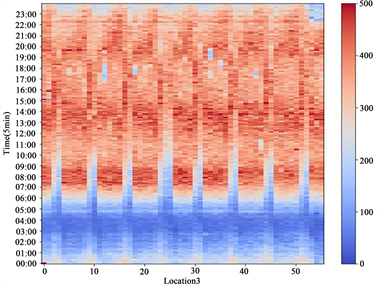
. traffic flow data for 56 days at detection point 3
图8. 位于检测点3的56天的交通流量数据
以上各式中,x表示真实交通流量值,y表示预测交通流量值,本文在实验过程中,为了证明算法的准确性,采取将一段时间内的真实交通流量值作为需要预测的交通流量值,从而可以实现预测值和真实值的对比。表展示了在基于完整数据情况下各算法的预测误差。表3显示了基于数据集各算法的预测误差。
. comparison of short-time traffic flow prediction algorithms
表3. 各短时交通流预测算法对比
从上表分析可以看出,文中提出的算法在不同短时预测的mape值和rmse值均为最小值,即文中提出的算法要优于传统的预测算法。
5. 结束语
智能交通系统在现代城市交通管理和控制中,扮演着非常重要的角色。它集成了现代信息与通信技术,通过数据采集、传输和分析,实现了交通设施设备之间的互联互通和智能化控制。本文针对智能交通系统中的数据分析领域,提出了基于张量分解的短时交通流预测方法。通过构建四维张量模型,覆盖周、天、时间窗口和空间,从而在保留原始数据结构的同时,更全面、更有效地挖掘交通数据之间的多模态相关性。这一四维张量模型不仅可以将交通数据的时间和空间信息整合起来,更重要的是能从不同视角全面反映交通数据之间的相互关系,实现对交通流量分析和预测的更准确和可靠。实验结果显示,张量tucker-als算法的预测效果优于其他算法,得到满意的预测结果。
notes
*通讯作者。